library(magrittr)
library(kableExtra)
burials %>% addmargins() %>%
kbl() %>%
kable_styling()| Pot | Cup | Fibula | Sum | |
|---|---|---|---|---|
| Burial1 | 1 | 1 | 0 | 2 |
| Burial2 | 0 | 1 | 1 | 2 |
| Burial3 | 1 | 1 | 1 | 3 |
| Burial4 | 1 | 0 | 1 | 2 |
| Sum | 3 | 3 | 3 | 9 |
The basic assumption underlying correspondence analysis is the same as the one we used in cluster analysis: similar things have similar characteristics, and can therefore be grouped together based on their features. Just like cluster analysis, correspondence analysis is a Pattern Detection technique. Both could also be called exploratory methods. Their aim is to discover patterns in the data. Using correspondence analysis as a statistical procedure does not in any way prove that the patterns found are actually significant. For the purpose of significance testing, one must resort to standard procedures of statistical hypothesis testing.
In contrast to cluster analysis, correspondence analysis is inherently a visual procedure. It is primarily used to visualise contingency tables or presents absence matrices. Correspondence analysis belongs to the broader field of ordination methods, which involves ordering objects according to their characteristics and then visually representing this order.
The basic idea of visualisation by means of a correspondence analysis is the following: the representation of the objects (called ‘sites’ in vegan jargon) and the properties (mostly types in archaeology, called ‘species’ in vegan jargon) are represented in a common coordinate system. The intuition here is that objects that are closer together should also be more similar than those objects that are positioned far away from each other. For this, of course, similarities must first be determined. This similarity determination is carried out in the context of the correspondence analysis by means of the chi-square method, as we have already become familiar with in the context of the chi-square test.
Just like the chi-square test, the correspondence analysis has very low requirements for the data quality of the variables due to the underlying mathematical method (the chi-square method). A data matrix with at least nominally scaled variables is sufficient for the procedure. Higher scaled variables are also possible, but then the information contained in this higher scale level is lost. These low demands on the scaling level make the correspondence particularly attractive for archaeological questions, as we often only have nominally scaled variables, such as different types at a site, or different nominally determined features on pottery vessels.
The basic sequence can be stated as follows. 1:
 .caption[.tiny[source: http://www.aapspharmscitech.org] ]
.caption[.tiny[source: http://www.aapspharmscitech.org] ]
 .caption[.tiny[source: http://www.cs.mcgill.ca]]
.caption[.tiny[source: http://www.cs.mcgill.ca]]
Correspondence analysis itself was developed in the context of biological and psychological studies. Its algebraic foundations were laid in the 1940s by Hartley and Guttmann. The first explicit use of correspondence analysis was by Benzéncri in the 1960s in the field of linguistic studies. Subsequently, correspondence analysis was further explored and developed by various research groups. This led to the emergence of different versions, but also to the establishment of different names for the same procedure. In 1984, Greenacre wrote the basic monograph on the method, which is still considered the standard work on the subject.
In archaeology, correspondence analysis appeared first and mainly in the context of seriation. Seriations were already carried out and published in 1899 by William Flinders Petri. However, these were still done by hand and eye, and were not yet supported by mathematical methods. In the 1960s, the application of various mathematical methods for seriation studies experienced a great upswing (Kendall, Münsingen). In Germany, the first experiments with seriation using computer-assisted methods were published by Goldmann in 1979 as part of his dissertation, in which the method of reciprocal averaging was used for seriation. Only subsequently did correspondence analysis emerge as a method for this purpose. This procedure was used particularly extensively in the chronological order of the Rhenish Linearband Pottery. The procedures used in this context were further developed especially by the University of Cologne. Another focus of the application of correspondence analysis in German-speaking countries is the University of Kiel.
For correspondence analysis, data is usually available in two-dimensional form: the individual rows of the data table represent the individual items. These can be individual sites, but also individual pottery vessels, depending on the scale of the respective investigation. The individual columns, in turn, represent the features that were observed on the individual items. Depending on the scale of the investigation, this can also reach very different levels of granularity.
The table can contain presence-absence data. Here, a one in the corresponding cell indicates that the feature is present on the object, whereas the zero represents the absence of this feature.
library(magrittr)
library(kableExtra)
burials %>% addmargins() %>%
kbl() %>%
kable_styling()| Pot | Cup | Fibula | Sum | |
|---|---|---|---|---|
| Burial1 | 1 | 1 | 0 | 2 |
| Burial2 | 0 | 1 | 1 | 2 |
| Burial3 | 1 | 1 | 1 | 3 |
| Burial4 | 1 | 0 | 1 | 2 |
| Sum | 3 | 3 | 3 | 9 |
Another possibility, which is particularly useful for more comprehensive analyses, is the representation as a contingency table: Here, an absolute number is used to indicate how many of the characteristics are observable on the respective item.
| Pot | Cup | Fibula | Sum | |
|---|---|---|---|---|
| Settlements | 20 | 23 | 40 | 83 |
| Hoards | 23 | 10 | 6 | 39 |
| Burials | 10 | 56 | 4 | 70 |
| Sum | 53 | 89 | 50 | 192 |
Another possibility how data can be used in a correspondence analysis is the so-called Burt matrix. In this case, features and items are no longer listed with respect to each other in a table, but only the correspondence between features matching items, or the correspondence between items matching features.
To illustrate this, let us transform the table of grave goods and individual burials from above into one respectively two Burt matrices. Let us start with the matrix for the items. For all burials, we look in pairs at how many present attribute values they match. This number marks the cell content for a table in which all items (in our case, burials) are plotted against each other in the rows and columns.
In the case of burial one, pot and cup are present. This means that burial one is assigned the value two in relation to burial one itself, since we have two positive feature values present. In relation to burial two, the value one is assigned, as both are in agreement positively only in relation to the cup. In relation to burial three, the value is again two, as both top and cup match, but burial one does not include a fibula. In relation to burial four, again, only the pot matches, cup and fibula are missing in one of the two graves respectively. This now continues for all pairwise items. At the end of this procedure we should arrive at the following table:
| Burial1 | Burial2 | Burial3 | Burial4 | |
|---|---|---|---|---|
| Burial1 | 2 | 1 | 2 | 1 |
| Burial2 | 1 | 2 | 2 | 1 |
| Burial3 | 2 | 2 | 3 | 2 |
| Burial4 | 1 | 1 | 2 | 2 |
Instead of counting out the individual values directly, we can also use an operation from matrix algebra: we multiply the matrix of presence-absence data by itself, with the second instance transposed, i.e. rotated by 90°. The result is the same as that of the process we performed by hand above.
burials %*% t(burials) Burial1 Burial2 Burial3 Burial4
Burial1 2 1 2 1
Burial2 1 2 2 1
Burial3 2 2 3 2
Burial4 1 1 2 2In this way we have created a Burt matrix for the sites. In the same way, we can also create a matrix for the features, i.e. the species. Only we have to exchange which of the matrices we rotate by 90°.
t(burials) %*% burials Pot Cup Fibula
Pot 3 2 2
Cup 2 3 2
Fibula 2 2 3The resulting matrices each record the relevant matches, but focus only on either the characteristics or the items. The diagonal contains the number of matches observed for the individual features or items with themselves. These are not actually relevant to the original problem of the seriation. Therefore, one can also set this diagonal to zero in order to focus even more strongly on the correlations between the individual variables or items. Such a modified Burt matrix can often give a clearer seriation and correspondence analysis result.
burt.s <- burials %*% t(burials)
diag(burt.s) <- 0
burt.s Burial1 Burial2 Burial3 Burial4
Burial1 0 1 2 1
Burial2 1 0 2 1
Burial3 2 2 0 2
Burial4 1 1 2 0In the next step, we bring the values within the data table (be it the presence absence or contingency table) to a uniform measure. Here we use the relative numbers per cell, i.e. we divide the total table by the total sum of all entries in this table.
Let us continue to illustrate this with the presence-absence table for the burials:
| Pot | Cup | Fibula | Sum | |
|---|---|---|---|---|
| Burial1 | 1 | 1 | 0 | 2 |
| Burial2 | 0 | 1 | 1 | 2 |
| Burial3 | 1 | 1 | 1 | 3 |
| Burial4 | 1 | 0 | 1 | 2 |
| Sum | 3 | 3 | 3 | 9 |
Here I have included the marginal sums. The total sum of the table is nine. If we now divide each individual cell of the table by nine, the total sum is only one, and the respective entries are one ninth.
| Pot | Cup | Fibula | Sum | |
|---|---|---|---|---|
| Burial1 | 0.11 | 0.11 | 0.00 | 0.22 |
| Burial2 | 0.00 | 0.11 | 0.11 | 0.22 |
| Burial3 | 0.11 | 0.11 | 0.11 | 0.33 |
| Burial4 | 0.11 | 0.00 | 0.11 | 0.22 |
| Sum | 0.33 | 0.33 | 0.33 | 1.00 |
In addition to the individual values within the table, which now represent the relative frequency, the newly created marginal sums are also relevant. We will need these to calculate the expected values for the Chi Square value. Furthermore, we will need this information later for scaling the coordinates for the visual representation. These marginal sums are also called row or column profiles, the individual values within these are also called row masses or column masses.
.tiny[ Row profile:
Burial1 Burial2 Burial3 Burial4
0.22 0.22 0.33 0.22 Column profile:
Pot Cup Fibula
0.33 0.33 0.33 The correspondence analysis, as already indicated several times, is based on the chi-square value in its measure for the individual similarities. We have covered the following formula for the calculation of the chi-square value within the chi-square test:
\(\chi^2=\sum_{i=1}^n \frac{(O_i - E_i)^2}{E_i}\)
So we relate the observed values to the expected values, assuming that no specific pattern exists, and thus measure the degree of our surprise with regard to the pattern in the data. For this calculation, we need the expected values as well as the observed values. In fact, the measure used in the correspondence analysis is a slight modification of the above formula: instead of the chi-squared value, we use a Z value that is not squared, which means that we can have positive and negative values.
\(z_{ij}=\frac{(O_i - E_i)}{\sqrt{E_i}}\)
Nevertheless, we also need the expected values for the calculation of this value, which, as you will remember from the lesson on the chiquadrat test, results from the marginal sums. In the case that no pattern exists, the expected value for the individual cell is the column sum times the row sum, divided by the total sum. The latter is omitted in our case here, since the total sum is already normalised to one. Thus, we can calculate the total expected value for the table quite quickly:
| Pot | Cup | Fibula | Sum | |
|---|---|---|---|---|
| Burial1 | 0.07 | 0.07 | 0.07 | 0.22 |
| Burial2 | 0.07 | 0.07 | 0.07 | 0.22 |
| Burial3 | 0.11 | 0.11 | 0.11 | 0.33 |
| Burial4 | 0.07 | 0.07 | 0.07 | 0.22 |
| Sum | 0.33 | 0.33 | 0.33 | 1.00 |
Now, with the expected values at hand, we can put them together with the observed values into the formula above. I will spare you the actual calculation, as we have already done this in a similar way for the chi-square test. Instead, below is just the table with the results for the normalised values:
| Pot | Cup | Fibula | Sum | |
|---|---|---|---|---|
| Burial1 | 0.14 | 0.14 | -0.27 | 0 |
| Burial2 | -0.27 | 0.14 | 0.14 | 0 |
| Burial3 | 0.00 | 0.00 | 0.00 | 0 |
| Burial4 | 0.14 | -0.27 | 0.14 | 0 |
| Sum | 0.00 | 0.00 | 0.00 | 0 |
The first thing we can derive directly from this table is the measure of the overall dispersion of the data. This means how much variability (or potential for surprise, to stick with the language I have now used more often) there is in our data set. The measure of surprise is, in fact, the chi-square value. To make this comparable between different data sets, we have to divide it by the number of cases. In purely mathematical terms (I will spare us all the derivation), however, we can also sum up the normalised values over the entire table and obtain the same number as a result. This can also be expressed as a formula, which looks quite impressive due to its two sums signs, but is basically quite trivial. The second part of the formula means nothing other than that all values are simply summed up over all rows and columns of the table.
\(I = \frac{\chi^2}{n} = \sum_i \sum_j z_{ij}^2\)
The result of this calculation is a measure of the dispersion of the data in relation to the number of cases. This measure is also called inertia. This term appears frequently when correspondence analysis is involved. It means nothing other than how volatile or dissimilar the individual data in the overall data set are to each other.
The total inertia in our example is: 0.3333333
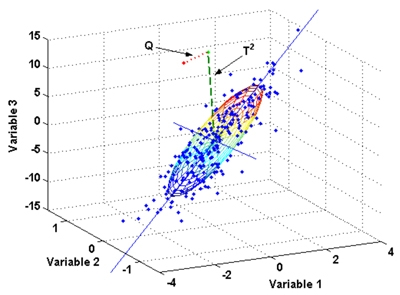
The second thing we can derive are the coordinates of our data in the multidimensional data space. This is nothing other than the values of the individual data sets in relation to the individual variables. In our case, these variables are normalised with the normalisation we just did. The individual axes, however, still correspond to the original variables that we have provided. This corresponds to the representation we have already used above (Figure \(\ref{multivariablespace}\)).
There are three variables in our data set. In a three-dimensional representation, we can now plot all three variables in a coordinate system and represent our points (our individual data) in it. In the HTML version of this book, the following picture is movable with the mouse: Just click on it, keep the mouse button pressed and move the mouse. I am not yet sure how to do this in the printed version.
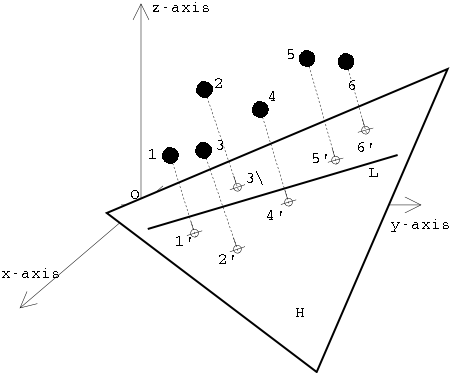
But this is exactly where the problem lies. Normally, we are not able to see all variables at the same time, even with a three-dimensional representation. Therefore, one of the most important concerns in correspondence analysis is to reduce the dimensions while at the same time reflecting as much information as possible. Correspondence analysis thus belongs to the so-called dimension reduction methods. As already explained above, we now look for the vectors that run through the largest scatter in our data cloud. The first vector to be determined is the one that covers the largest extent and thus also absorbs the most variability in the data set. The next vector is determined in such a way that it lies at right angles to the first, and at the same time runs through the next largest possible extent of the data cloud. And so on.
Two vectors in space describe a plane. So once we have determined the first and second vectors, we can use these two to define a plane that represents our future coordinate space. The vectors themselves become the axes of the new coordinate system. Projected perpendicularly onto this plane (as if you were looking at it from above, or as if you were shining a torch on the scenery from above so that the data points cast shadows), the individual data points can now be represented on this plane. And with this, we have obtained a new view of our data, in which the greatest dissimilarities are mapped via the vectors. So we get a representation that captures as much of the information of the original data set as possible, but does it with only two dimensions. And this can be done for any combination of vectors (dimensions).
.caption[.tiny[source: http://www.cs.mcgill.ca]] ]
Mathematically, this determination of the largest extension of the point cloud and the projection of the points onto the resulting vectors is the solution of a complex linear equation system. And a proven means for such a task is the so-called singular value decomposition (SVD). This method is used in many fields, ranging from image compression methods such as JPEG, to the reconstruction of three-dimensional objects, to such esoteric applications as particle physics. In our humble use case, it is used to perform data reduction. But because of the importance of this process in many areas, one of its developers (Gene Golub) has appropriated the abbreviation for his car registration plate:
 .caption[.tiny[Gene Golub’s license plate, photographed by Professor P. M. Kroonenberg of Leiden University.]]
.caption[.tiny[Gene Golub’s license plate, photographed by Professor P. M. Kroonenberg of Leiden University.]]
Specifically, the data matrix of our similarities is decomposed into three matrices.
\(Z=U∗S∗V'\)
Z : Matrix with the standardized data (our input)
U : Matrix for the row elements
V : Matrix for the column elements
S : Diagonal matrix with the singular values
Z are the normalised values we calculated above. Three matrices are created from these. U is the matrix that gives the new coordinates on the vectors for the rows of our original data (i.e. the cases, in our case the burials). V is in the same sense the matrix for the columns, in our case the different types. These can also be oriented in the coordinate system, so to speak as an ideal case for the occurrence of this form. We can determine similarities of the objects in relation to their properties, but in the same framework we can also determine similarities of the properties in relation to the objects in which they are represented. The last matrix S is a diagonal matrix, i.e. it consists almost exclusively of zeros, only its diagonal has values. In our case, these values represent the information about how much of the variability of the total data set is included in the individual dimensions of the new coordinate system. If all three matrices are multiplied together by means of matrix multiplication, the initial matrix Z is obtained again.
How this matrix decomposition works is hard to do and even harder to understand if you haven’t done a semester of matrix algebra. Fortunately, R takes care of that for us. And of course, as we will see later, there is also a command that does all the correspondence analysis for us in one piece. Nevertheless, we will proceed step by step here, and first perform the singular value decomposition for our normalised data:
burial.z<-read.csv2("burial_z.csv",row.names=1)
burial.svd<-svd(burial.z)
burial.svd$d
[1] 4.082483e-01 4.082483e-01 1.005681e-15
$u
[,1] [,2] [,3]
[1,] -7.071068e-01 -4.082483e-01 -0.5530935
[2,] -1.367413e-16 8.164966e-01 -0.5530935
[3,] 2.077635e-17 6.299174e-32 0.2868150
[4,] 7.071068e-01 -4.082483e-01 -0.5530935
$v
[,1] [,2] [,3]
[1,] 0.0000000 -0.8164966 0.5773503
[2,] -0.7071068 0.4082483 0.5773503
[3,] 0.7071068 0.4082483 0.5773503SVD and Inertia The singular values (eigenvalues) represent the inertia. The eigenvalues
burial.svd$d[1] 4.082483e-01 4.082483e-01 1.005681e-15The squared eigenvalues are the inertia of the individual dimensions
burial.svd$d^2[1] 1.666667e-01 1.666667e-01 1.011395e-30The sum of the squared eigenvalues is equal to the total of the intertia.
sum(burial.svd$d^2)[1] 0.3333333If the inertia of the individual dimensions is divided by the total inertia, the (eigenvalue) proportion of the dimensions is obtained.
burial.svd$d^2/sum(burial.svd$d^2)[1] 5.000000e-01 5.000000e-01 3.034184e-30Scaling of the coordinates in such a way that
The dimensions are weighted according to their proportion of the total inertia.
The rows/columns are weighted according to their proportion of the mass.
.pull-left[
Row (sites) Points: \(r_{ik} = \frac{u_{ik}*\sqrt{s_k}}{\sqrt{p_i}}\)
] .pull-right[
Column (species) Points: \(c_{jk} = \frac{v_{jk}*\sqrt{s_k}}{\sqrt{p_j}}\)
]
\(u\), \(v\) → Matrices of rows/columns from the SVD
\(s_k\) → Diagonal matrix
\(p_i\) , \(p_j\) → Masses of rows/columns from the relative frequency
Everything in R:
.pull-left[
library(vegan)
burial <- read.csv("burials.csv",
row.names = 1)
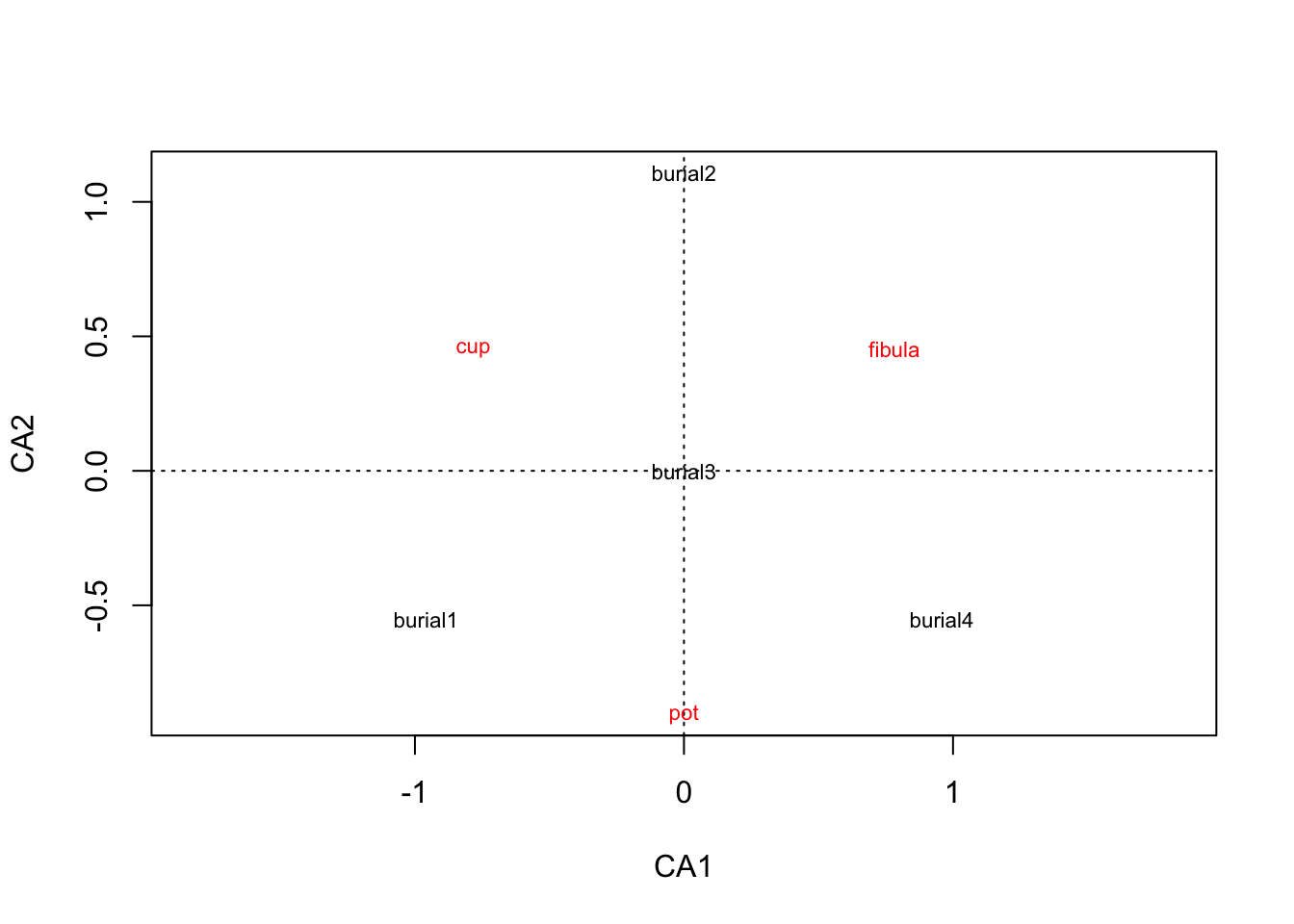
burial.cca <- cca(burial)
plot(burial.cca, scaling=3)scaling=3: by default R normalizes only the species (types)
scaling = 1 : Normalization of sites
scaling = 2 : Normalization of the Species
scaling = 3 : Symmetrical normalization of sites and species
scaling = 0 : No normalization ]
.pull-right[
]
.pull-left[ .small[
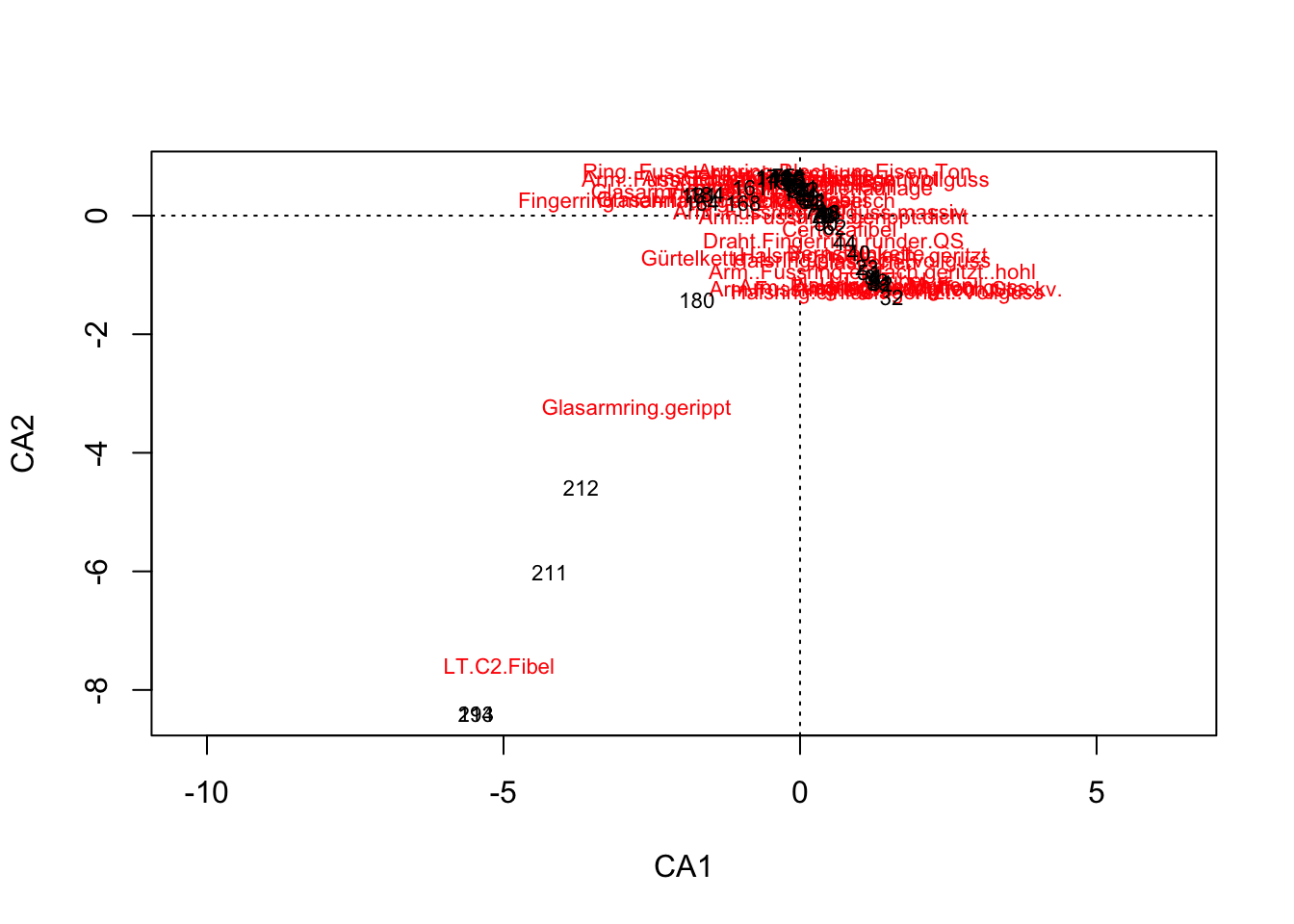
muensingen <- read.csv("muensingen_ideal.csv",
row.names = 1)
muensingen.cca <- cca(muensingen)
plot(muensingen.cca, scaling=3)] ]
.pull-right[
]
.pull-left[ .tiny[
scores(muensingen.cca, display = "sites") CA1 CA2
32 1.606313e+00 -1.452925953
31 1.417566e+00 -1.191711661
8b 1.335804e+00 -1.088200431
12 1.415720e+00 -1.195513769
8a 1.381076e+00 -1.183971647
6 1.318179e+00 -1.097469151
9 1.305596e+00 -1.130528153
23 1.172513e+00 -0.912136067
44 7.886929e-01 -0.469460799
51 1.207199e+00 -0.998288130
40 1.032187e+00 -0.663168035
28 4.135180e-01 0.009305833
62 6.073775e-01 -0.192755350
91 2.594931e-01 0.273907559
72 3.852720e-01 0.009685198
80 4.578284e-01 -0.135341372
46 4.999726e-01 0.062684002
48 4.999726e-01 0.062684002
49 4.664078e-01 0.040744687
68 2.368297e-01 0.259427802
79 2.812150e-01 0.075938349
61 1.788927e-01 0.267615201
102 1.720921e-02 0.473091324
81 -5.781215e-02 0.535954589
84 -4.796386e-05 0.457809401
86 1.289481e-01 0.324469138
130 -2.266955e-01 0.659478553
136 -1.993537e-01 0.662413700
140 -2.351985e-01 0.669474019
135 -2.284840e-01 0.688394387
121 -3.173622e-03 0.500283343
145 -2.413927e-01 0.629709178
75 -2.814656e-01 0.701537467
98 -4.340398e-02 0.475096777
134 -2.593867e-03 0.404872794
157 -3.108071e-01 0.614129078
161 -8.740028e-01 0.494958429
171 -4.762109e-01 0.691500466
180 -1.801351e+00 -1.487499183
181 -1.765745e+00 0.359016975
164 -1.721644e+00 0.225999084
168 -9.925575e-01 0.232793904
149 -4.501877e-01 0.660128687
184 -1.631521e+00 0.375301510
211 -4.377063e+00 -6.322384039
212 -3.835635e+00 -4.831052095
193 -5.668999e+00 -8.843550371
214 -5.668999e+00 -8.843550371] ]
.pull-right[ .tiny[
scores(muensingen.cca, display = "species") CA1 CA2
LT.A.Fibel 1.26553218 -1.02575507
Halsring.einfach.geritzt..Vollguss 1.42268370 -1.23712903
Arm.Fussring.einf...vollg.loch.Steckv. 1.39589208 -1.19799158
Arm..Fussring.einfach.geritzt..hohl 1.17884979 -0.91744662
Glasperlen 1.05767259 -0.76556860
Bernsteinkette 0.90576411 -0.59674656
Arm..Fussring.gerippt.vollguss 1.36065846 -1.16302096
Hirschgeweih 1.36694980 -1.14649146
Halsring.m..Muffen 1.34962749 -1.14072040
Armring.mit.Muffen 1.38107585 -1.18397165
Draht.Fingerring.runder.QS 0.54905934 -0.42294391
Arm..Fussring.vollguss.massiv 0.30773335 0.02653237
Halsring.plastisch..vollguss 0.99794588 -0.73387446
Halsring.hohlblech..geritzt 1.03218740 -0.66316804
Arm..Fussringe.gerippt.dicht 0.54345897 -0.03844059
Certosafibel 0.63923617 -0.20818750
Schwert 0.26898152 0.14758021
Kette -0.08973973 0.23569196
Lanze 0.20230485 0.23181940
LT.B1.Fibel 0.21181418 0.25693309
Armreif.mit.Korallenauflage 0.04601620 0.42893018
Fingerring.flachblech -0.09756829 0.46147527
Schaukelfingerringe -0.32647874 0.58102969
Arm..Fussring.plastisch.gerippt -0.15984628 0.57814339
LT.B2.Fibel -0.31048691 0.58499166
Arm..Fussring.genoppt..plastisch..Vollguss -0.23211926 0.55870602
Ring..Fuss..Armring.Blech.um.Eisen.Ton -0.36582667 0.68083308
Hohlbuckelarmringe -0.34680816 0.65312662
Fingerring.mehrfach.gewickelt.plastisch -1.51503177 0.21905089
LT.C1.Fibel -1.47959077 0.33836796
Glasarmring.gerippt -2.65992172 -3.09912747
Glasarmring.genoppt -1.76574493 0.35901698
Glasarmring.Fadenauflage -1.23558643 0.23052896
Gürtelkette -1.72630918 -0.66736578
LT.C2.Fibel -4.88767414 -7.21013422] ]
.pull-left[ .tiny[
plot(muensingen.cca, display = "sites")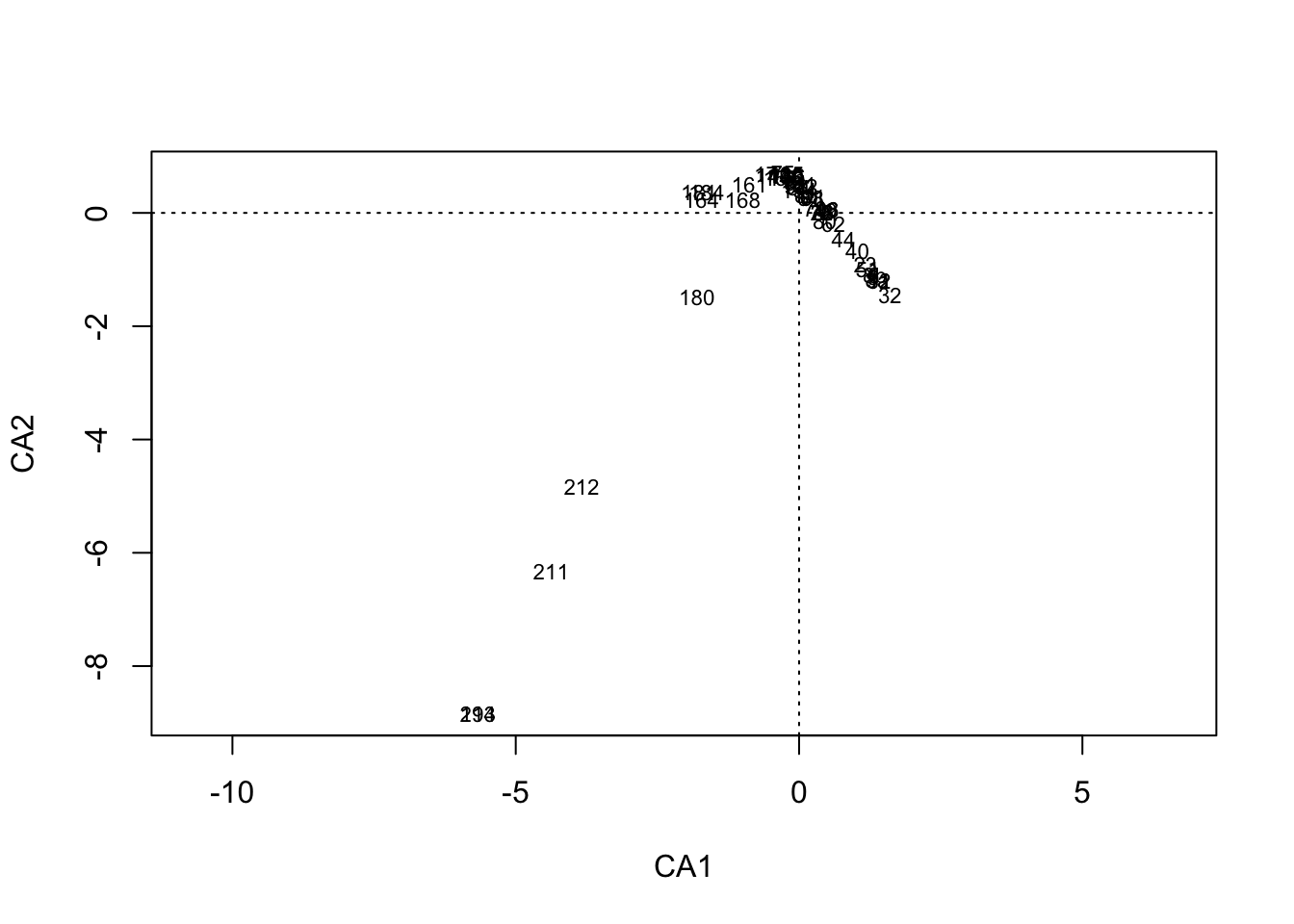
] ]
.pull-right[ .tiny[
plot(muensingen.cca, display = "species")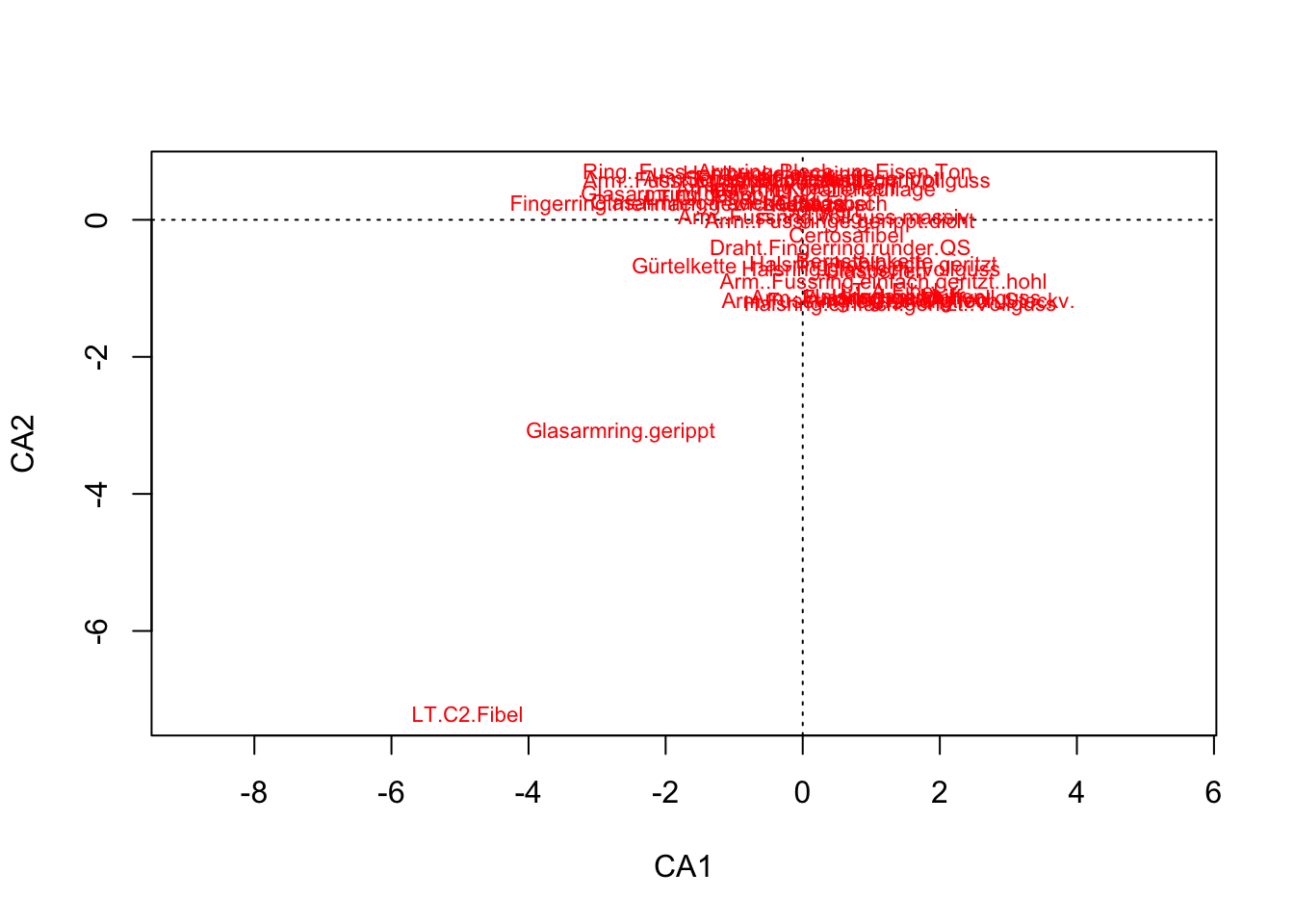
] ]
.pull-left[ .tiny[
plot(muensingen.cca, choices = c(1,2))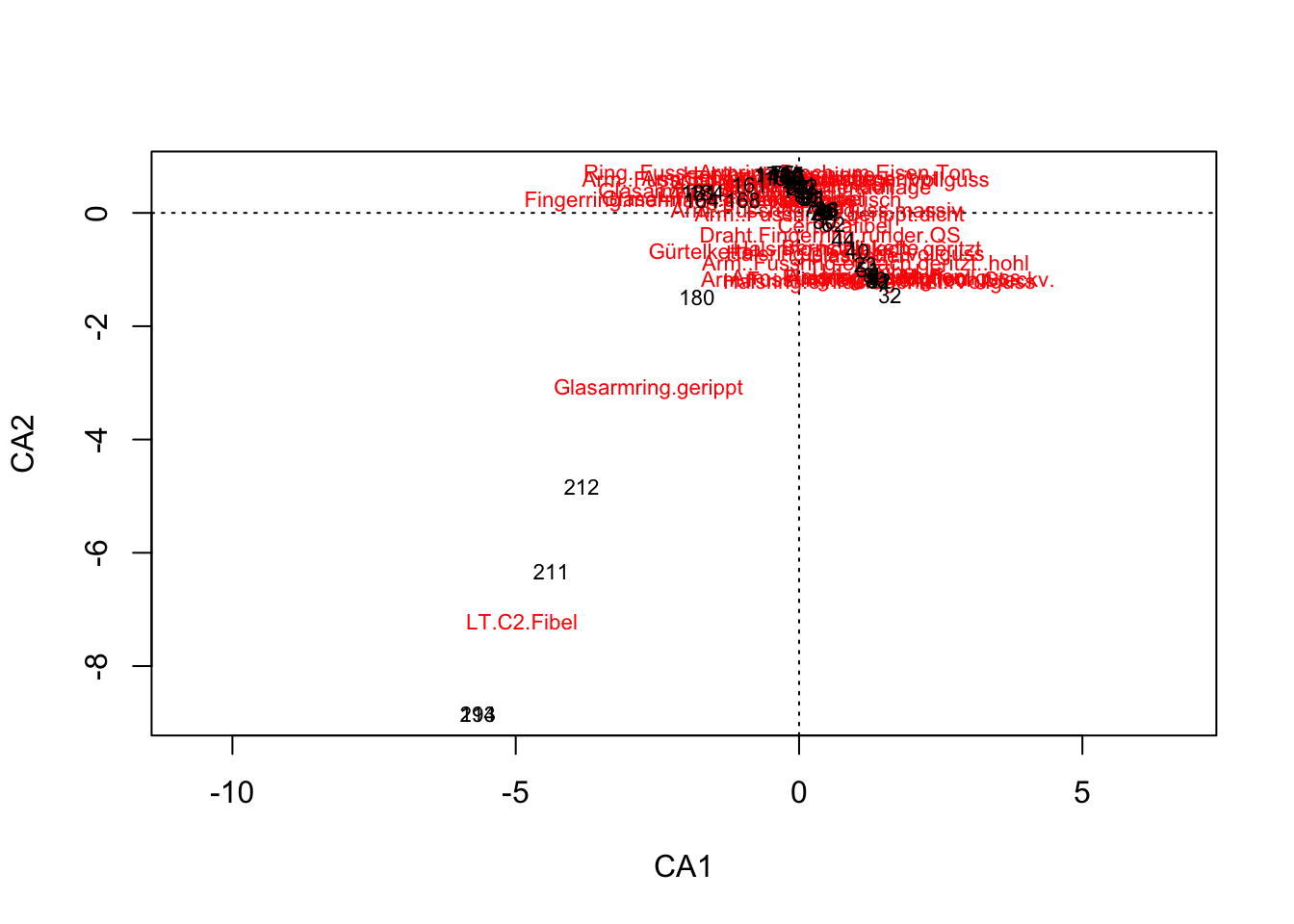
] ]
.pull-right[ .tiny[
plot(muensingen.cca, choices = c(1,3))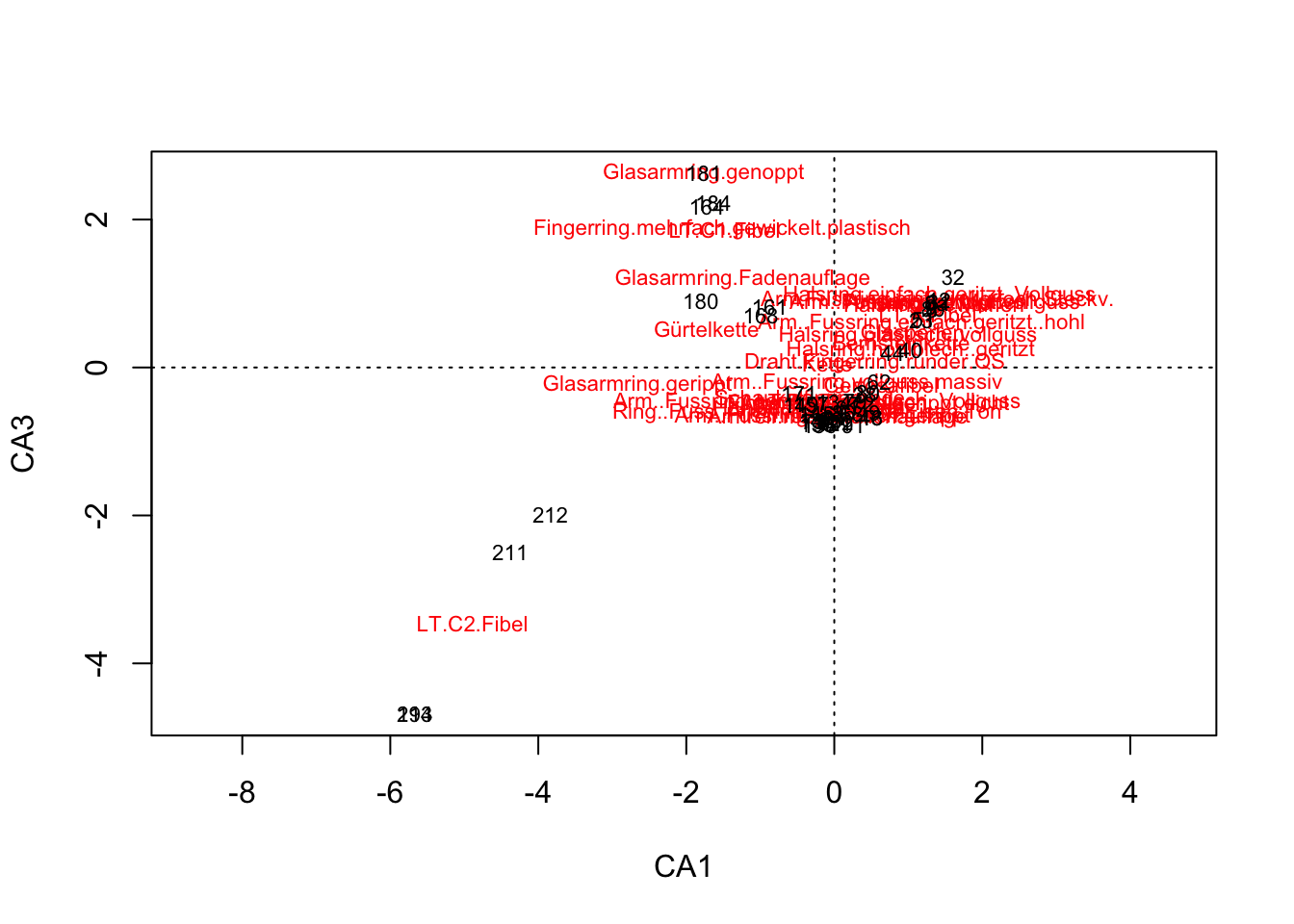
] ]
.pull-left[ .tiny[
library(ggplot2)
library(ggrepel)
muensingen.species <- data.frame(
scores(muensingen.cca)$species
)
ggplot(muensingen.species,
aes(x=CA1,
y=CA2,
label=rownames(muensingen.species))) +
geom_point() + geom_text_repel(size=2)] ]
.pull-right[
Warning: ggrepel: 17 unlabeled data points (too many overlaps). Consider
increasing max.overlaps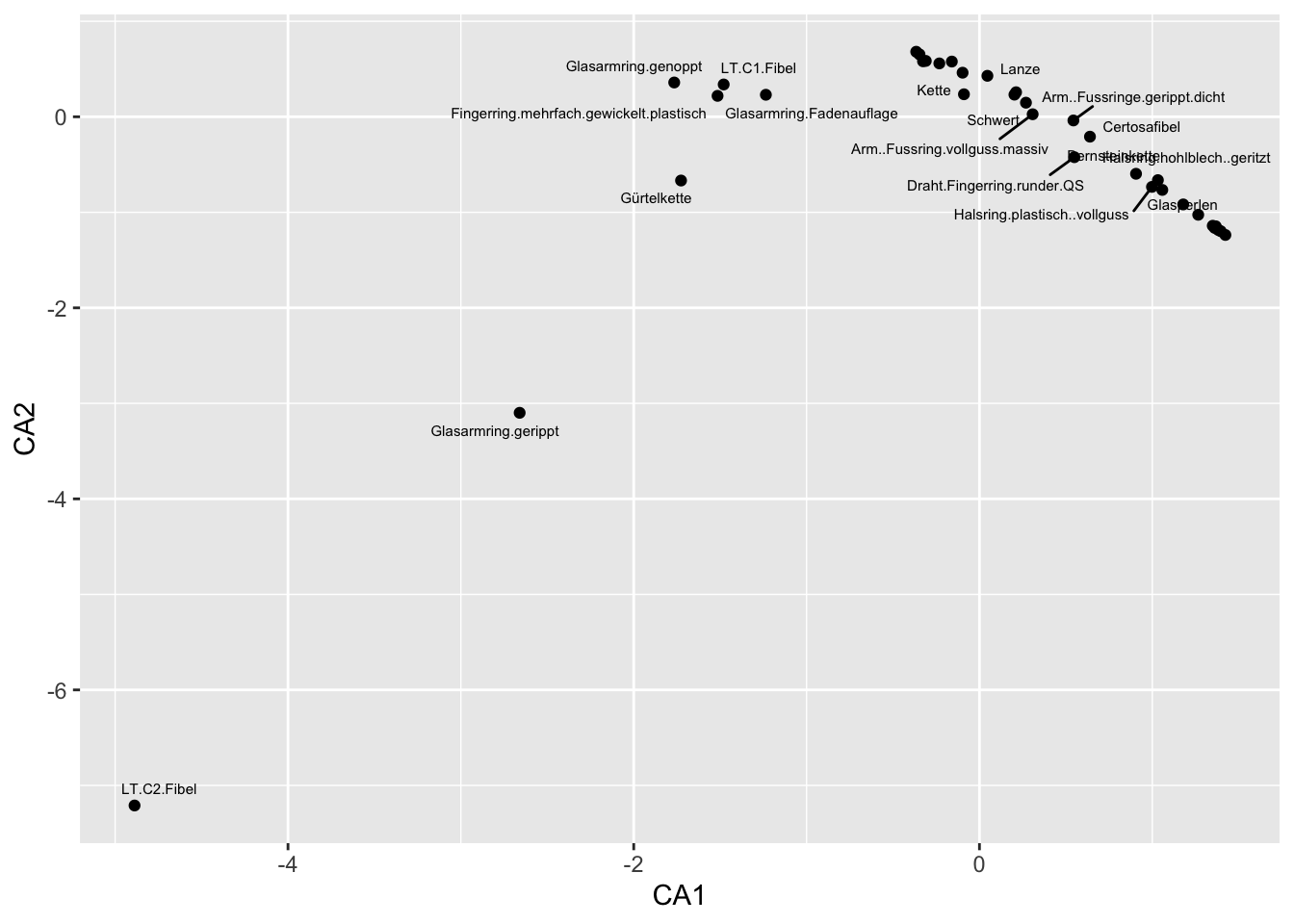
]
.pull-left[ 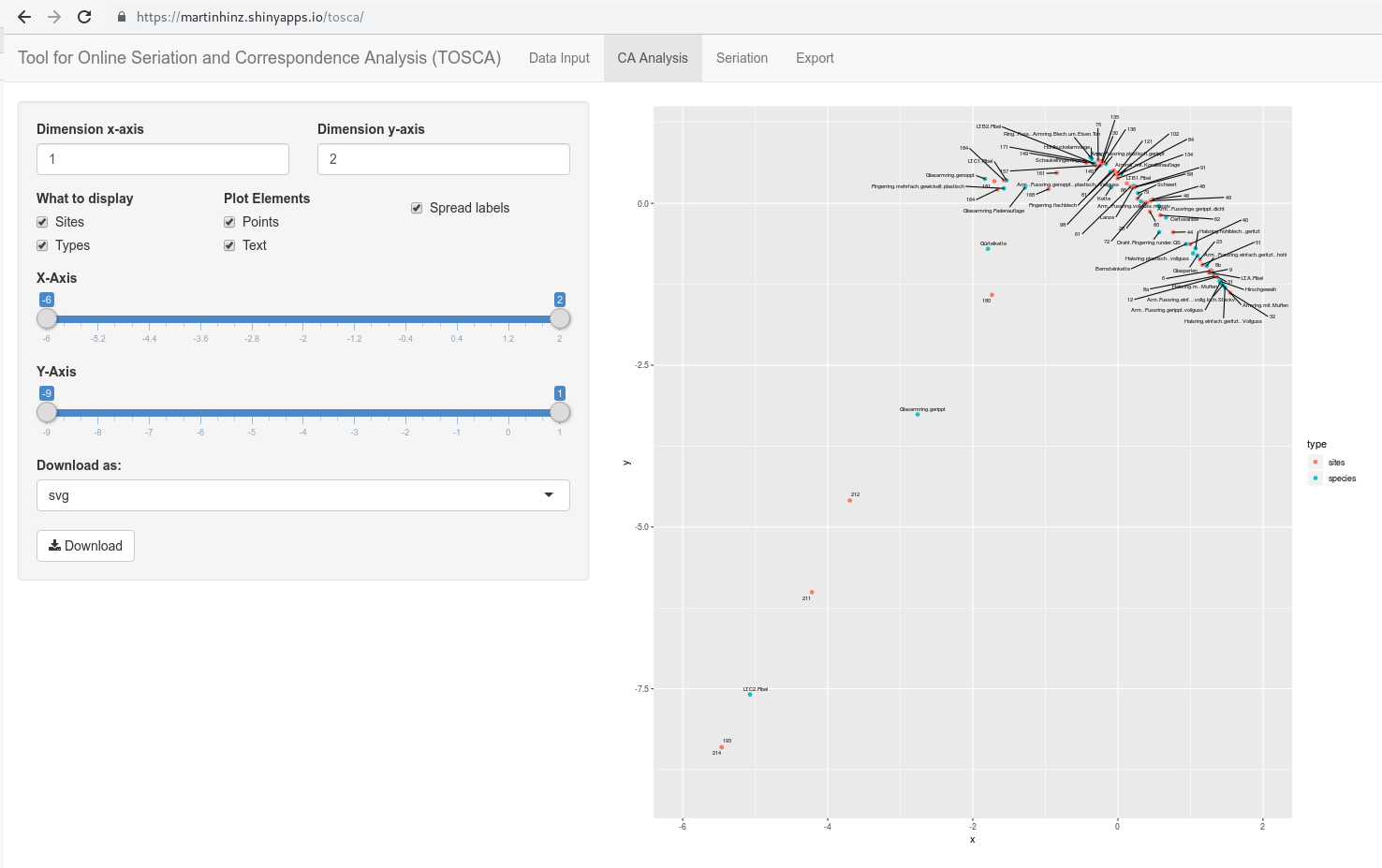 ]
]
.pull-right[ 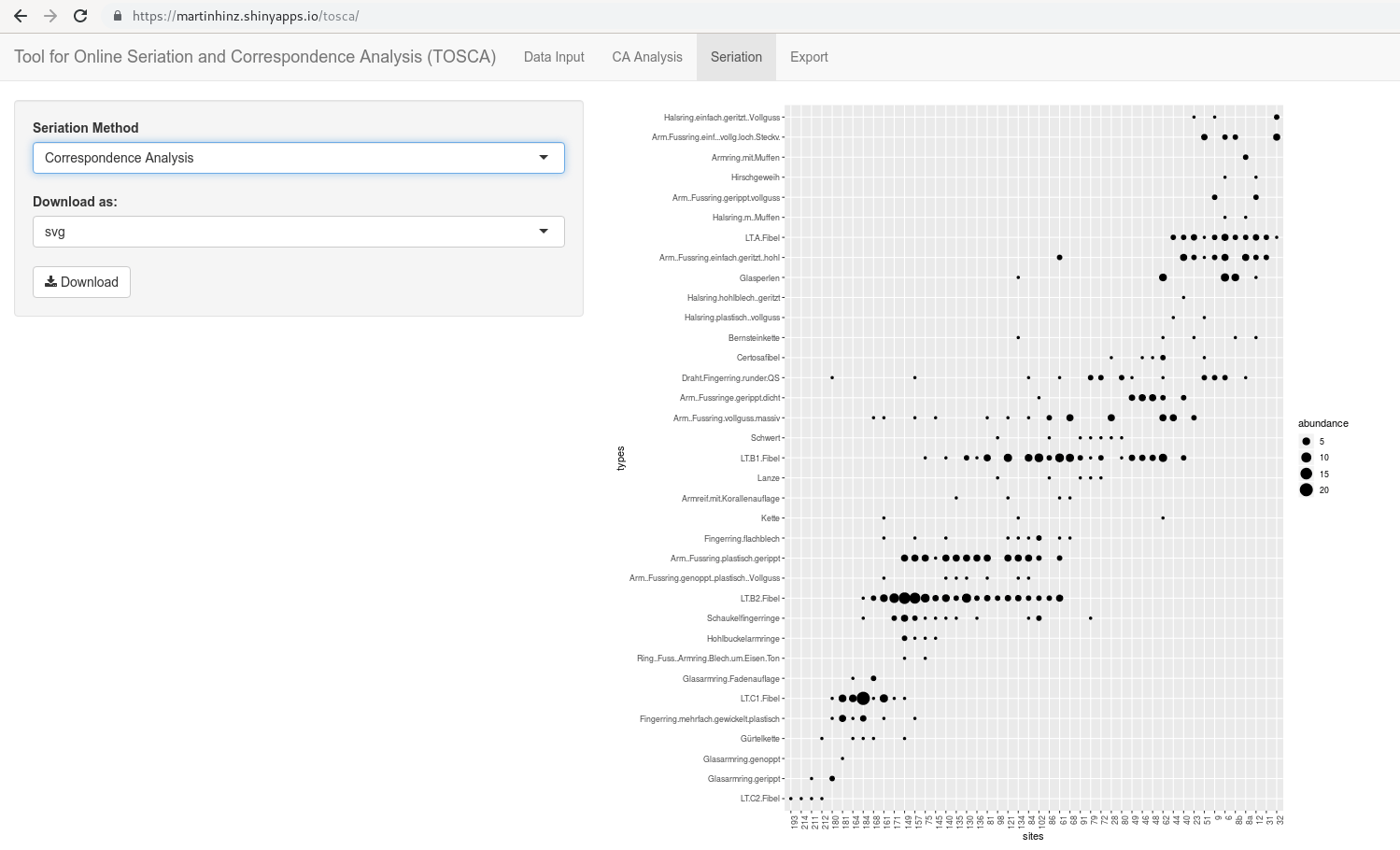 ]
]
.pull-left[ In archaeology, this is often regarded as evidence of a temporal orientation.
The Guttman effect occurs when a process affects the data on multiple levels.
The largest influencing factor, given a longer runtime, is mostly the time, but:
This does not always have to be the case.
Check against other information necessary. ]
.pull-right[
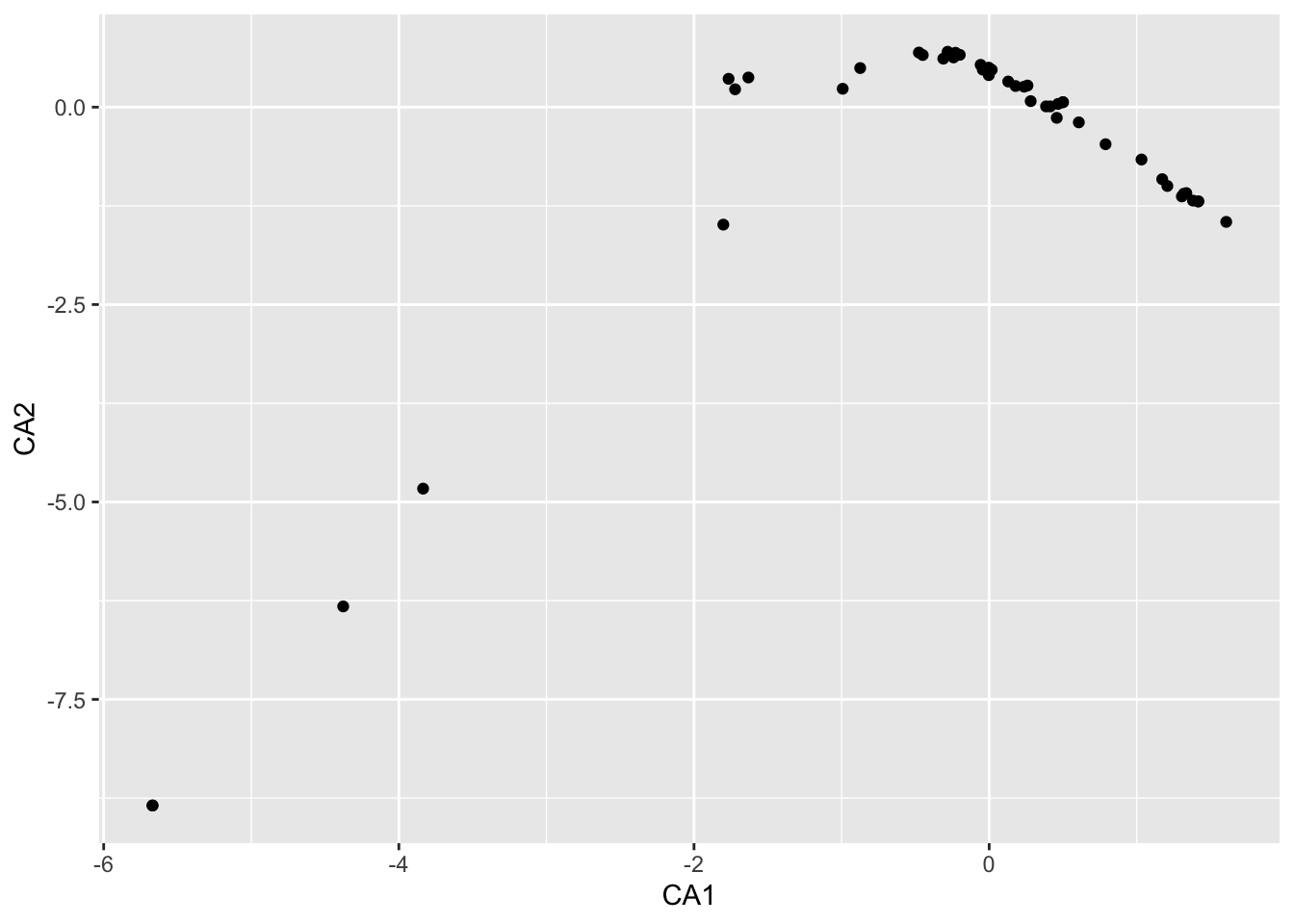
]